





赛道 | 深兰包揽SIGIR eCOM'21双赛道冠军 自研自动特征工程框架神助攻
日前,信息检索领域的国际重要会议SIGIR 2021正在线上举行,深兰科技DeepBlueAI团队参加了SIGIR eCom'21 竞赛,与来自NVIDIA、eBay、华东师范大学、乐天等知名企业和学校的团队同台竞技,并在竞赛仅设的两个赛道中均获得冠军。
这是DeepBlueAI团队继2019年获得该系列比赛冠军以来的第二次夺冠,证明了深兰在电商推荐系统领域的技术有着领先的地位。此外,更值得注意的是在第二个赛道,深兰自研的自动特征工程框架助力队伍获得了冠军,证明了其自动化机器学习的强大能力。
SIGIR eCom'21 竞赛由Coveo承办,是在2021 SIGIR Workshop on eCommerce上组织的一场电商商品推荐的比赛。该比赛从2017年开始,每年举办一次,今年已是第5届。
冠军方案解读
赛题介绍
SIGIR eCom'21 竞赛分为两个赛题:
第一、商品推荐任务。赛题把一个会话分成前后两部分,给出前面一部分的数据,要求预测出后面会交互的商品,是一个大数据量的推荐问题。
第二、购买意图预测任务。赛题给出一个有添加购物车行为的会话的前面一部分,要求预测最后用户是不是真的会买这个商品,是一个二分类问题。
团队成绩
比赛竞争非常激烈,最终DeepBlueAI团队击败了NVIDIA团队,在两个任务都取得了冠军。
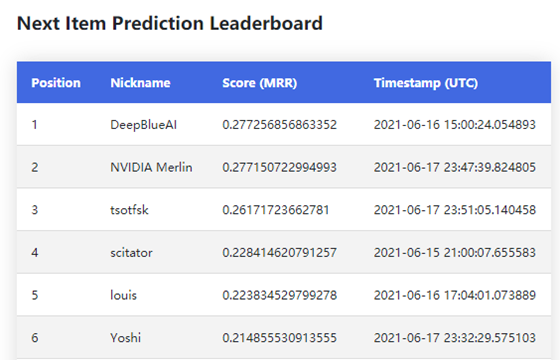
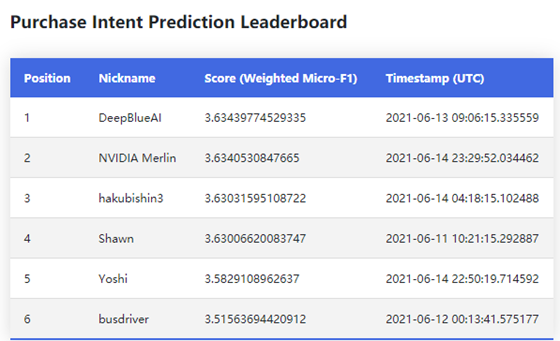
数据分析
两个任务使用的是同一批数据,训练集测试集合起来一共有600多万,其中有100万会话数据和6万多个商品。经过分析,这两个任务分别有以下难点。
对于商品推荐任务:
首先数据量很大,需要对代码质量要求很高;
第二有30%的测试集会话,给的初始信息很少,怎么有效优化冷启动的会话,提升得分?
第三原始数据给出的字段极为丰富,怎么有效利用这些信息?
对于预测购买意图任务,主要是这个任务的评分指标很复杂:
首先,它定义了一个k,k表示第一次添加购物车之后会话还有几条记录。评分指标要求对k越小的样本预测正确奖励越高,针对这一点,怎么设计模型或者策略能够适应这个机制?
第二,每个k是一个分类,最终得分是每个类样本的平均准确率之和。因为使用了准确率(accuracy),加上正负样本不平衡,导致对模型的精度要求非常高。
竞赛方案
对于商品推荐任务,团队整体采用召回+排序的框架。
排序方面,团队尝试了很多方法,但是提升的效果有限。召回在这个任务里更为重要,在尝试了很多种方法后,团队最终使用了两个效果较好的召回。
1. u2i_interact_i2i_itemcf:
先通过协同过滤的方法算出item与item之间的相似度,然后根据user历史交互的item,推荐与它最相似的item。
2. u2url_url2i:
先统计访问当前url之后,下次访问每个item的概率;然后根据用户最后一个url推荐那些概率大的item。
对于预测购买意图任务:
首先是特征工程,团队采用了手动特征与自动特征工程相结合的方式。手动特征方面,主要是提取一些比较明显有效的特征,如用户是否查看了添加购物车商品的细节、查看了多久、用户一共交互了多少商品等比较直观的特征,效果上评分指标提升0.008;自动特征工程则是利用深兰自研autosmart框架提取的特征,这一部分特征效果提升0.002。
然后是后处理方面,针对评分指标的特性,基于k值不同对每个分类单独进行阈值调整,达到本地最好效果。
-

8项冠亚季军收官ECCV2020,深兰获三大视觉顶会挑战赛大满贯
计算机视觉 -
与腾讯、哈工大同台竞技,深兰获自然语言处理领域国际顶会NAACL2021冠军
计算机视觉 -

捷报 | 深兰科技“双队”出征CVPR2021 斩获五冠共获14项大奖
计算机视觉 -

2022CVPR传捷报丨深兰科技再度折桂,连续4届获得CVPR挑战赛冠军
计算机视觉 -

深兰科技夺冠CCKS2022“带条件的分层级多答案问答”评测任务竞赛
自然语言处理 -
PK 656 个对手!深兰科技在全球顶级AI赛事kaggle竞赛中再次夺冠
计算机视觉 -

一冠三亚二季!深兰科技在EMNLP2022国际顶级赛事再创佳绩
数据挖掘 -

6个奖项!深兰科技在CVPR 2023挑战赛中再获佳绩
计算机视觉 -

6冠3亚2季!深兰科技在RANLP2023国际赛事上斩获11项大奖
计算机视觉